The End of Robotic Voices: How Amazon Is Fixing LLM-Based Text-to-Speech

Quick Summary (TL;DR)
• The Problem with AI Voices: Today's LLM-based text-to-speech (TTS) sounds natural but often fails with accent leakage in other languages, a lack of human emotion, and unreliable performance like repetitions or sudden cutoffs.
• Amazon's Fixes: They're using a three-part strategy: LoRA fine-tuning to fix accents, Classifier-Free Guidance (CFG) to add expressiveness (like sighs and laughs), and Chain-of-Thought reasoning to make the AI "think before it speaks," drastically reducing errors.
• Why It Matters for eCommerce: High-quality, reliable AI voice builds brand trust, enables global expansion without embarrassing language gaffes, and creates more engaging customer experiences. The tech is finally getting good enough for primetime.
—
Ever been on a customer service call and the automated voice sounds like a hostage reading a script at gunpoint? Or tried an audiobook voiced by an AI that pronounces “read” and “read” the same way, turning a dramatic novel into a confusing mess? We've all been there. For years, the promise of human-like AI voice has felt just out of reach, plagued by robotic monotones and awkward phrasing.
Large Language Models (LLMs) were supposed to change that. And they did, to an extent. The latest text-to-speech systems can clone a voice from a few seconds of audio and sound incredibly natural. But beneath that smooth veneer, major problems persist. The AI might speak Spanish with a thick American accent, narrate a thrilling scene with the emotional range of a toaster, or just start repeating a word over and over like it's buffering. These aren't just minor glitches; they're deal-breakers for any brand that cares about its image.
But what if there was a way to fix it? Researchers at Amazon are tackling these issues head-on with a fascinating toolkit of advanced AI techniques. They're not just patching the system; they're fundamentally rethinking how AI learns to speak. This is the story of how we get from clunky, unreliable bots to expressive, dependable, and multilingual AI voices that can finally deliver on their promise.
What Exactly is LLM-Based Text-to-Speech (and Why Should You Care?)
Think of traditional text-to-speech as a meticulous but uninspired actor who just reads lines from a script. It stitches sounds together based on rigid rules. LLM-based text-to-speech, on the other hand, is like a seasoned improv artist. It has been trained on an enormous library of human speech and text—the internet, audiobooks, podcasts—and has learned the patterns, rhythms, and emotions of how people actually talk.
Instead of just converting text to phonemes, it generates speech autoregressively, meaning one tiny piece at a time, predicting the next sound based on the context of what it just said. This is why it can sound so fluid and natural. For eCommerce brands, this isn't just a cool tech demo; it's a tool for creating a consistent, scalable, and high-quality brand voice across every customer touchpoint, from marketing videos to support channels.
The High Stakes of Getting AI Voice Right
In a crowded digital marketplace, your brand's voice is its personality. Getting it wrong isn't just a technical failure; it's a business failure. Here’s why nailing LLM-based text-to-speech is so critical.
Building Brand Trust: From Monotone to Memorable
A flat, robotic voice screams "we don't care." It creates a subconscious barrier between you and your customer, making your brand feel distant and impersonal. Conversely, a warm, expressive, and reliable voice builds an emotional connection. It can make your brand feel more human, trustworthy, and memorable. Imagine a product tutorial that sounds genuinely enthusiastic or a welcome message that feels personal. That's the power of high-quality TTS.
A study by CGS found that 86% of consumers are willing to pay more for a better customer experience. A brand's voice is a fundamental part of that experience.

Global Expansion Without the Gaffes: Speaking Your Customer's Language (Properly)
Expanding into new markets is tough. The last thing you need is your AI assistant butchering the local language. The "accent leakage" problem is a classic example: your AI tries to speak German but retains a clunky American accent, instantly alienating local customers. True polyglot TTS—where a cloned voice can speak multiple languages like a native—is the holy grail. It ensures your brand maintains its unique vocal identity while showing respect for local culture and nuance. It’s the difference between being seen as a global brand and a foreign invader.
The Playbook: Amazon's Three-Pronged Attack on Bad AI Audio
So, how do you solve these deep-rooted problems? Amazon's approach isn't a single magic bullet but a combination of clever techniques that address each failure mode specifically.
Step 1: Fixing the Accent Problem with LoRA
The first challenge is teaching an AI a new language without it sounding like a tourist. The solution is a technique called Low-Rank Adaptation (LoRA).
Think of a massive, multilingual LLM as a world-class chef who knows every cuisine. If you want them to master a specific regional dish—say, authentic Neapolitan pizza—you don't reteach them how to cook from scratch. Instead, you give them a short, intensive training session with a master pizzaiolo.
LoRA does the same for the AI model. It freezes the huge, pre-trained model and adds a tiny, trainable layer on top. By fine-tuning only this small layer on high-quality, locale-specific data (e.g., authentic French audio), the model learns the correct accent and pronunciation without forgetting its core knowledge or the original speaker's voice identity. It's an incredibly efficient way to achieve accent-free polyglot voice cloning.
Key Tip: Don't rely on a generic model for multilingual content. Use models fine-tuned with techniques like LoRA to ensure native-like pronunciation and preserve brand voice consistency across regions.
Step 2: Injecting Emotion with Classifier-Free Guidance (CFG)
Natural speech is full of emotion—laughs, sighs, hesitations, and shifts in tone. Autoregressive LLMs can technically produce these, but they often play it safe, defaulting to a neutral delivery. To fix this, Amazon uses Classifier-Free Guidance (CFG).
CFG acts like an "expressiveness dial." During generation, it pushes the model to lean more heavily into the emotional cues present in the training data. By feeding it synthetic reference audio with enhanced expressive styles, the model learns to generate speech that is not just accurate but also engaging. It’s the difference between an AI stating, "This is funny," and an AI that actually laughs.
Key Tip: For marketing or customer-facing content, use TTS systems that employ techniques like CFG. The ability to control expressiveness allows you to match the audio's tone to the context, whether it's an upbeat ad or an empathetic support message.
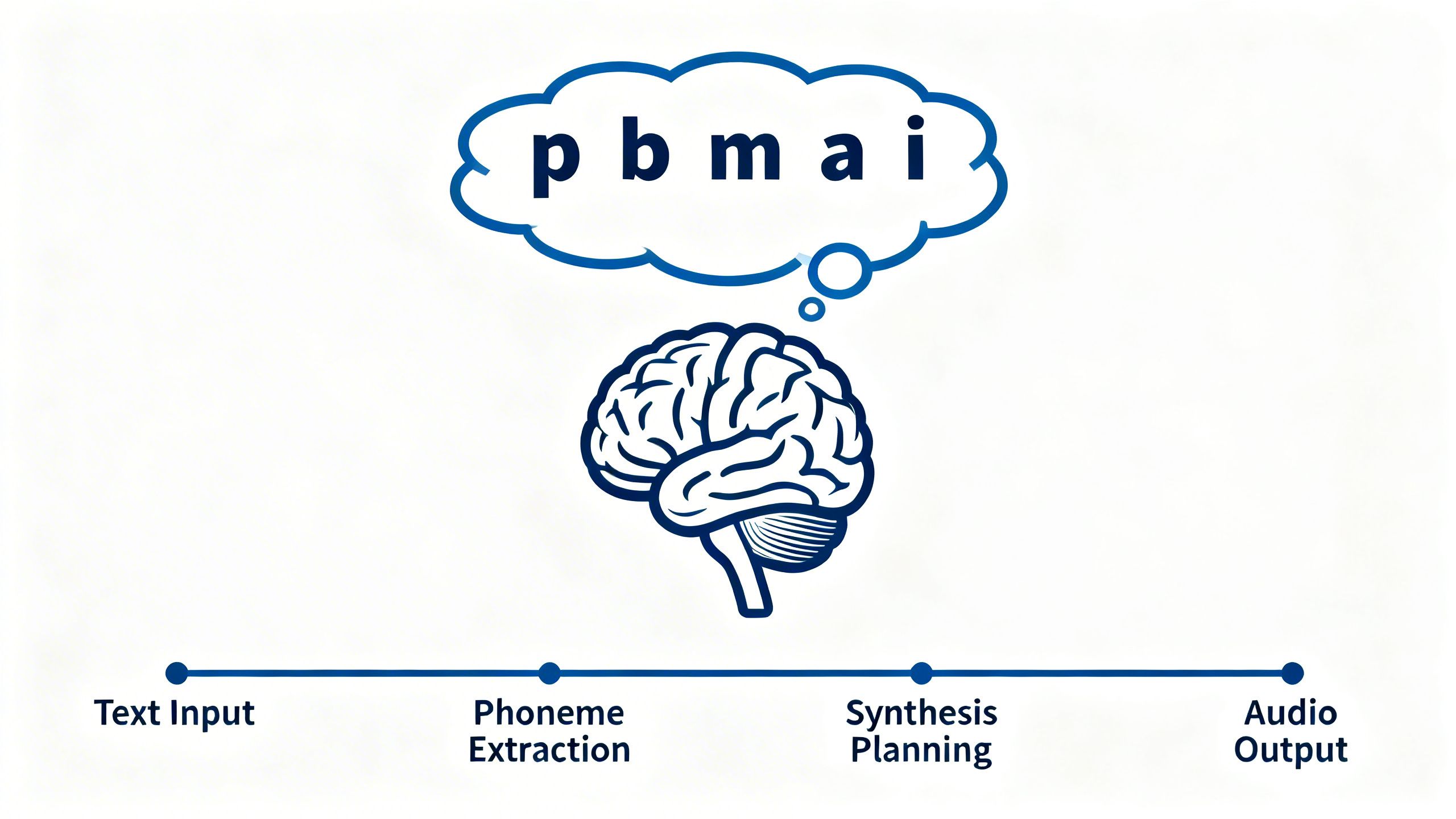
Step 3: Taming the Beast: Achieving Reliability with Chain-of-Thought
This is perhaps the most groundbreaking fix. The biggest reliability issue with autoregressive models is that they generate speech one token at a time with no master plan. This can lead to them getting lost, repeating words, or stopping mid-sentence. It's like a builder laying bricks without a blueprint.
The solution is to give the AI a blueprint. By implementing Chain-of-Thought (CoT) reasoning, the model is forced to "think before it speaks." Before generating a single sound, it first completes two internal steps:
- Predicts the Phoneme Sequence: It converts the input text into a sequence of phonetic sounds.
- Estimates the Duration: It plans out how long the entire utterance should be and how long each phoneme should last.
This internal monologue acts as a guide. The model now has a clear start and end point, which dramatically reduces hallucinations and random cutoffs. As a bonus, this "thought process" is visible to developers, making it much easier to debug when things go wrong.
LLM-Based Text-to-Speech: Best Practices in Action
Polyglot Voice Cloning Done Right
The real magic happens when you combine these techniques. With LoRA, you can take a voice recorded in American English and transfer it to Spanish or German. The cloned voice speaks the new language with a native accent, yet it's still recognizably the same speaker. For a global brand, this means you can have your CEO's voice deliver a message in multiple languages, all while sounding authentic and maintaining the unique timbre of their voice.
The Power of Expressive Audio in Marketing
Imagine running a dynamic ad campaign where the voiceover is tailored to the user. With CFG, you can generate thousands of variations of an ad read—some excited, some calm, some humorous—and test which one performs best. Or consider an eCommerce site where product descriptions can be read aloud with genuine enthusiasm. This level of personalization and emotional resonance was impossible with old TTS systems.
From the Lab to the Real World: Case Studies

eCommerce: Personalizing the Shopping Experience
A high-end fashion retailer wanted to make their online product videos more engaging. Previously, they used a standard, neutral TTS voice that made their luxury products feel cheap. By switching to an LLM-based system with CFG, they generated voiceovers in a sophisticated, aspirational tone. They A/B tested the new videos and saw a 15% increase in average watch time and a 5% lift in add-to-cart rates. The voice itself became part of the premium experience.
Customer Support: Reducing Frustration with Empathetic AI
A telecom company was plagued by low customer satisfaction scores for its automated phone system. Customers found the robotic voice frustrating and unhelpful. They implemented a new system using Chain-of-Thought for reliability and CFG for expressiveness. The new AI could adopt a calm, empathetic tone when a customer reported an issue. If it detected frustration, it could adjust its prosody to be more reassuring. The result? A 20% reduction in customers demanding to speak to a human agent for simple queries and a significant jump in CSAT scores.
Common Pitfalls in Deploying TTS and How to Sidestep Them
The 'One-Model-to-Rule-Them-All' Fallacy
Many companies make the mistake of grabbing a single, massive, general-purpose AI and expecting it to solve every problem. But as research shows, these models are often a master of none. When it comes to specialized tasks like generating accent-free polyglot audio, a generic model will almost always fail. As detailed in "How Agentic AI Is Revolutionizing eCommerce Security", using specialized agents or models for specific tasks is far more effective. The same principle applies here: you need models that are fine-tuned for the unique demands of high-quality voice generation.
Ignoring the 'Garbage In, Garbage Out' Rule
An LLM is only as good as the data it's trained on. If your training data is full of transcription errors, mispronunciations, or flat, emotionless audio, your TTS output will be too. Amazon's approach includes a sophisticated data filtering pipeline that uses both speech recognition and the LLM's own attention mechanisms to weed out bad data. This ensures the model learns from clean, high-quality examples, preserving expressiveness while catching errors.
Why TrackIQ Matters: Connecting Voice Data to Business Intelligence
So, you've deployed the world's most advanced, expressive, and reliable LLM-based text-to-speech system. Your product videos sound amazing, and your customer support bot is winning awards for its empathy. But here's the million-dollar question: is it actually working?
Is that sophisticated voiceover on your new product listing actually driving sales? Is the empathetic support bot reducing churn? Generating great audio is only half the battle. To understand its true business impact, you need to connect the dots between your new voice strategy and your core business metrics.
This is where a platform like TrackIQ becomes essential. While TTS systems generate the audio, TrackIQ provides the intelligence layer to measure its effectiveness. You can't just deploy new tech and hope for the best; you need to ask critical business questions. With TrackIQ's AI-powered agent, you can move from data dumps to actual decisions.
Instead of digging through spreadsheets, you can ask plain-English questions like:
"Compare the conversion rates for products using the new expressive voiceover versus the old one for the last 30 days."
Or
"What was the customer satisfaction score for interactions handled by the AI voice assistant this month, and how does it correlate with first-contact resolution?"
TrackIQ helps you understand the ROI of your technology investments. By learning how it works, you can see how it turns raw Amazon data into clear, actionable answers, ensuring your cutting-edge voice strategy translates into real, measurable growth.
Key Takeaways for Your Audio Strategy
- Focus on Specialization: Stop trying to use a single, general LLM for everything. For high-stakes applications like voice, invest in specialized models fine-tuned with techniques like LoRA to handle specific challenges like polyglot audio.
- Embrace 'Thinking' AI: The future of reliability lies in models that plan before they act. Chain-of-Thought reasoning is a game-changer, drastically reducing the errors that have made businesses hesitant to adopt LLM-based TTS.
- Measure Everything: Deploying new technology is not the finish line. You must pair your innovations with a powerful analytics platform to measure their impact on your KPIs. If you can't measure it, you can't optimize it.
Conclusion
The journey of text-to-speech is a perfect metaphor for the evolution of AI itself—from rigid, rule-based systems to fluid, learning organisms. We are finally moving past the era of clunky, robotic voices. Thanks to advancements like LoRA, CFG, and Chain-of-Thought reasoning, LLM-based text-to-speech is becoming robust, expressive, and reliable enough for mission-critical applications.
For eCommerce brands, this opens up a new frontier for building brand identity, personalizing customer experiences, and expanding globally. But deploying the tech is just the first step. The real winners will be those who not only adopt these powerful tools but also rigorously measure their impact. By pairing your advanced audio strategy with a smart analytics engine like TrackIQ, you can ensure your voice is not just heard, but that it drives results.
—