The AI Diet: How 'Pruning' Your Language Models Makes eCommerce Tools Faster, Smarter, and Cheaper

Quick Summary (TL;DR)
• What is LLM Pruning?: Think of it as a diet for the massive AI models that power your favorite tools. It strategically removes unneeded parts to make the AI faster and more efficient without losing its intelligence.
• Why It Matters for Sellers: A “pruned” AI means the software you use for analytics, advertising, and operations runs faster, costs less to operate (savings that can be passed to you), and delivers insights in seconds, not minutes.
• The New Hotness: A new philosophy called “Prune Gently, Taste Often” is revolutionizing this process, allowing for rapid AI optimization. This is the secret sauce behind the next generation of powerful, accessible eCommerce tools.
—
You ever feel like you’re living in the future, but the future is kind of… laggy? We’ve got AI that can write poetry and design ad campaigns, but sometimes waiting for a data report to load feels like dialing up AOL in 1998. For eCommerce sellers, speed is money. A slow analytics platform or a clunky ad management tool doesn’t just test your patience—it costs you opportunities.
The culprit is often the sheer size of the Large Language Models (LLMs) powering these tools. They’re massive, resource-hungry beasts. But what if there was a way to put these AI giants on a diet? A way to make them leaner, meaner, and faster, without sacrificing their brainpower?
That’s exactly what LLM pruning is. It’s the behind-the-scenes magic that’s about to make your entire tech stack feel like it got a major upgrade. This isn’t just abstract tech talk; it’s the reason your next AI co-pilot will be a lightning-fast genius instead of a sluggish robot. Let's break down what it is and why it’s a game-changer for your bottom line.
What the Heck is LLM Pruning, Anyway?
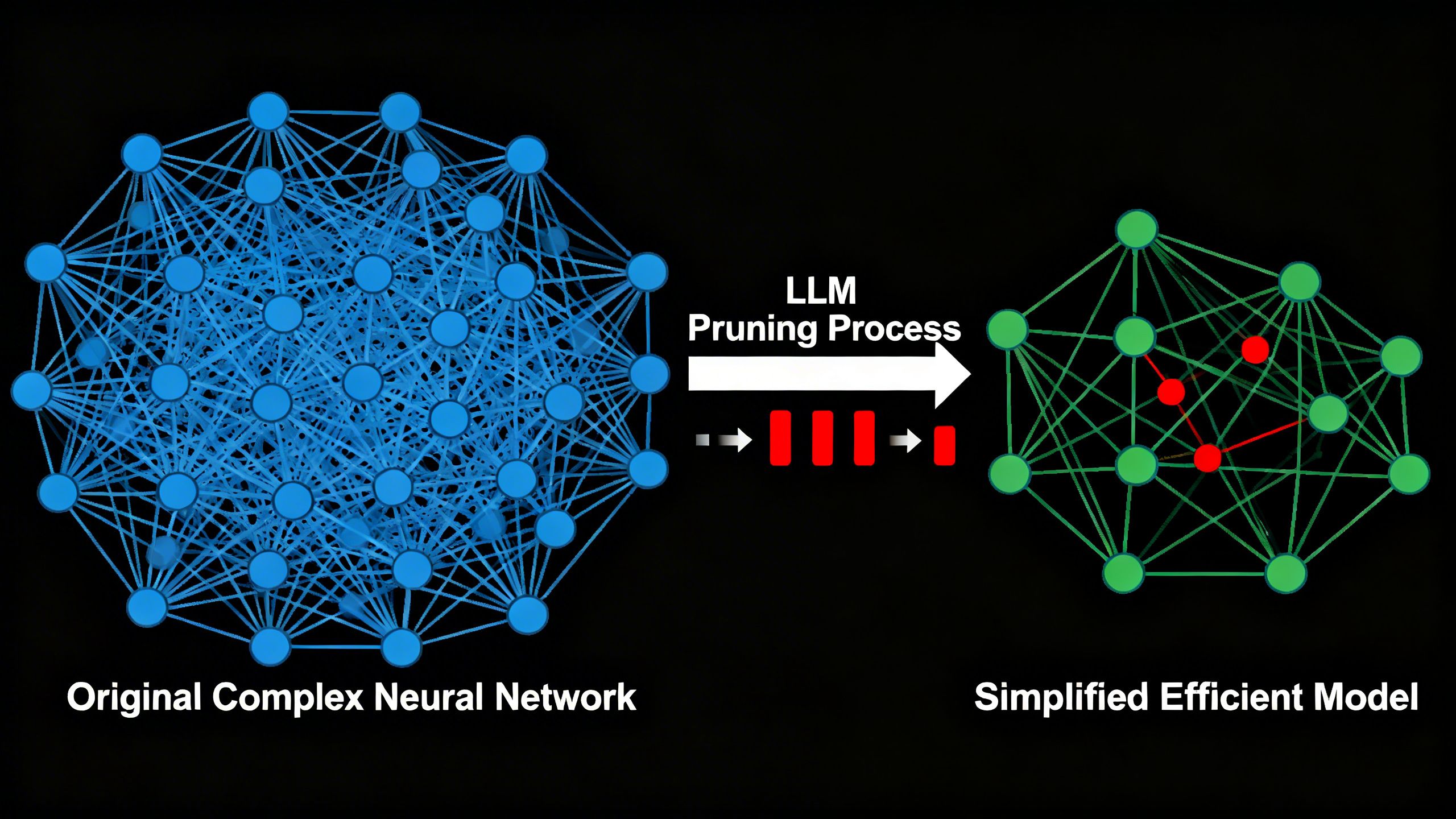
In the simplest terms, LLM pruning is the process of trimming the fat from an AI model. When an LLM is trained, it develops billions of connections, or “parameters,” within its neural network. Think of it like a massive, overgrown jungle of information. Many of these connections are critical, but a surprising number are redundant or just plain useless—like knowing 50 different ways to say “hello” but not knowing how to calculate your profit margin.
Pruning identifies and removes these unimportant connections. The result is a smaller, more compact model that performs the same tasks but with a fraction of the computational horsepower. It’s like taking a 1,000-page encyclopedia and condensing it into a 100-page field guide that gives you the exact answers you need, instantly.
“Pruning is a compression process that removes unimportant connections within the layers of an LLM’s neural network.” — Amazon Science
This isn’t about making the AI dumber. It’s about making it more efficient. A well-pruned model can lead to faster runtimes, lower energy consumption, and cheaper operational costs for the companies providing you with AI-powered services.
Why Should a Seller Care? The ROI of a Lean AI
This all sounds great for AI researchers, but what’s the tangible benefit for an Amazon seller trying to hit their quarterly numbers? It’s simple: better, faster, cheaper tools.
Blazing-Fast Performance: From Hours to Seconds
A leaner AI model means the tools you rely on daily get a massive speed boost. Imagine asking your analytics platform a complex question like, “Which of my products are losing profitability due to rising ad costs on weekends?” and getting an answer in real-time. That’s the power of an optimized AI. It replaces hours of manual data-crunching with instant, actionable insights.
This speed translates directly to agility. You can react to market changes, pounce on keyword opportunities, and adjust ad budgets before your competitors have even finished loading their spreadsheets. This is the competitive edge that separates 7-figure sellers from 8-figure sellers.
Lower Operational Costs: A More Accessible AI Future
Running massive LLMs is incredibly expensive, requiring huge amounts of computational power. These costs are inevitably baked into the subscription fees you pay for software. When a company uses pruned, efficient models, their operational costs go down. This makes it possible to offer incredibly powerful AI tools at a more accessible price point.

Furthermore, it democratizes access to advanced AI. You no longer need an enterprise-level budget to leverage the kind of AI that was once exclusive to giants like Amazon. This efficiency is what allows platforms like TrackIQ to provide sophisticated AI analytics that feel like having a data scientist on call 24/7, without the six-figure salary.
The Chef's Guide to AI Optimization: How Pruning Works
The concept of pruning isn’t new, but the way it’s done is undergoing a revolution. The old methods were clumsy and often did more harm than good.
The Old Way: All-or-Nothing Pruning
Previously, there were two main approaches to pruning, and both had serious drawbacks:
- Pruning During Training: This is like trying to diet while you’re still learning to eat. It’s baked into the AI’s initial learning process, but it’s computationally expensive and requires endless trial and error.
- Post-Training Pruning: This is more like a crash diet. After the AI is fully trained, engineers would slash a huge number of connections at once. It was cheaper, but it “shocked” the model, causing a significant drop in accuracy.
The Chef Analogy: Imagine making a complex soup. The old methods are like either dumping a pile of salt in at the very beginning and hoping for the best, or forgetting the salt entirely and then trying to stir in a cup of it right at the end. Either way, you’re probably ruining the soup.
The New Philosophy: 'Prune Gently, Taste Often'
A new framework, nicknamed Wanda++, introduces a brilliant philosophy: “Prune Gently, Taste Often.” Instead of hacking away at the entire model at once, it breaks the AI down into smaller, manageable chunks called “decoder blocks.”
Here’s how it works:
- Isolate a Block: It focuses on one small part of the AI model.
- Prune Gently: It carefully removes the unimportant connections within just that single block.
- Taste Often: It then immediately calibrates the remaining connections with a small amount of data, ensuring the block’s performance is restored or even improved.
- Repeat: It moves to the next block and repeats the process.
Key Tip: This block-by-block approach is like a master chef seasoning a dish. They add a little spice, taste it, adjust, and repeat until it’s perfect. It avoids the “shock” of the old methods and results in a highly optimized model that retains its accuracy. The result? A model with 7 billion parameters can be compressed in under 10 minutes on a single GPU.
The Result: A Perfectly Seasoned AI
This methodical approach preserves the model's overall quality while dramatically increasing its efficiency. It’s a middle path that combines the best of both worlds: the low cost of post-training pruning with the high performance of more integrated methods. This is the technical innovation that enables the development of sophisticated yet nimble agentic AI systems that can act as your co-pilot.
LLM Pruning in Action: From Theory to Your P&L
So, how does a faster, leaner AI actually help you sell more on Amazon?
Smarter Ad Bidding and Keyword Discovery
Your PPC campaigns generate a mountain of data every single day. A pruned AI can sift through this data in near real-time to identify negative keywords that are draining your budget, spot emerging long-tail keywords your competitors have missed, and automatically adjust bids based on performance trends. Instead of waiting 24 hours for a report, you get insights that allow you to optimize your campaigns on the fly, maximizing your ROAS. This is how top Amazon sellers dominate PPC.
Hyper-Personalized Customer Interactions
Whether it’s through an on-site chatbot or automated email follow-ups, a fast AI can deliver hyper-personalized experiences without lag. It can analyze a customer’s search history, past purchases, and browsing behavior to offer relevant product recommendations or answer specific questions instantly, increasing conversion rates and customer satisfaction.
Why TrackIQ Matters: Putting Efficient AI to Work
This entire discussion about LLM pruning isn't just theoretical—it's the foundational principle behind how modern eCommerce tools should be built. At TrackIQ, we are obsessed with efficiency, not just for our AI models, but for your business.
We believe that the purpose of AI isn't to overwhelm you with data, but to provide clear, immediate answers to your most pressing questions. Our platform is built on the idea that a powerful AI should feel like an intuitive co-pilot, not a complex piece of machinery.
From Complex Data to Simple Conversation
The “Prune Gently, Taste Often” philosophy mirrors our own approach. We process your complex Amazon data, but what we deliver to you is a simple, conversational interface where you can ask questions and get answers. You don't need to be a data scientist to use TrackIQ; you just need to know your business. Our AI does the heavy lifting—efficiently and in the background.
An Agent That Works for You
This efficiency is what makes it possible for TrackIQ to act as a true agentic AI for eCommerce. It doesn’t just show you a graph; it surfaces insights you didn’t even know to look for, monitors your P&L for anomalies, and helps you make decisions that directly impact your growth. By leveraging lean, powerful AI, we deliver a service that replaces hours of manual work every week, giving you back time to focus on strategy.
Common Misconceptions About AI in eCommerce
The Myth: Bigger is Always Better
Many sellers believe that the most powerful AI must come from the biggest, most expensive models. But LLM pruning proves this is false. For specialized tasks like Amazon analytics or PPC optimization, a smaller, fine-tuned, and expertly pruned model will almost always outperform a generic, bloated one. It’s about having the right tool for the job, not the biggest one.
The Myth: AI is a 'Set It and Forget It' Magic Bullet
While AI can automate a huge number of tasks, it’s a co-pilot, not an autopilot. The “taste often” part of the pruning philosophy is a great metaphor for how sellers should approach AI. You need to constantly provide feedback, ask the right questions, and use the insights to inform your strategy. The AI provides the data-driven intelligence; you provide the human expertise.
The Future is Lean: What's Next for eCommerce AI?
The principles of LLM pruning are paving the way for even more exciting advancements. The next frontier is creating a Mixture of Experts (MoE)—a system where multiple small, specialized AI models work together.

Imagine having one expert AI for inventory forecasting, another for competitor price tracking, and a third for optimizing your product listings. These lean, expert models can collaborate to run your entire operation with unparalleled efficiency. This is the future that technologies like LLM pruning are making possible.
Your Key Takeaways on LLM Pruning
- Efficiency is the New Superpower: The best AI tools aren't the biggest; they're the fastest and most efficient. LLM pruning is the key to achieving this.
- Better Tools, Better Price: This technology directly leads to faster, more powerful, and more affordable software for sellers, democratizing access to high-level analytics.
- AI is Your Co-Pilot: The goal of AI is to give you back time and provide clear, actionable insights. Embrace tools that feel intuitive and conversational, not complex and overwhelming.
Conclusion
While “LLM pruning” might sound like a term reserved for Silicon Valley engineers, its impact is set to ripple across the entire eCommerce landscape. It’s the invisible engine that will power the next generation of tools that help you run your business more profitably and with less friction. The future of AI in eCommerce isn’t just about raw power; it’s about intelligent, efficient, and accessible power.
By understanding the importance of a lean and agile AI, you can better choose the tools and partners that will help you scale. The robots aren't just coming; they're getting smarter, faster, and ready to work for you. It's time to leverage them.
—